在 Linux 上使用 gImageReader 从图像和 PDF 中提取文本
简介:gImageReader 是一个 GUI 工具,可利用 tesseract OCR 引擎在 Linux 中从图像和 PDF 文件中提取文本。
gImageReader 是 Tesseract 开源 OCR 引擎的前端。 Tesseract 最初由 HP 开发,并于 2006 年开源。
基本上,OCR(光学字符识别)引擎可让您扫描图片或文件 (PDF) 中的文本。它默认可以检测多种语言,还支持通过 Unicode 字符进行扫描。
然而,Tesseract 本身是一个没有任何 GUI 的命令行工具。因此,gImageReader 可以帮助任何用户利用它从图像和文件中提取文本。
让我强调一下有关它的一些事情,同时提及我测试它时的体验。
gImageReader:Tesseract OCR 的跨平台前端
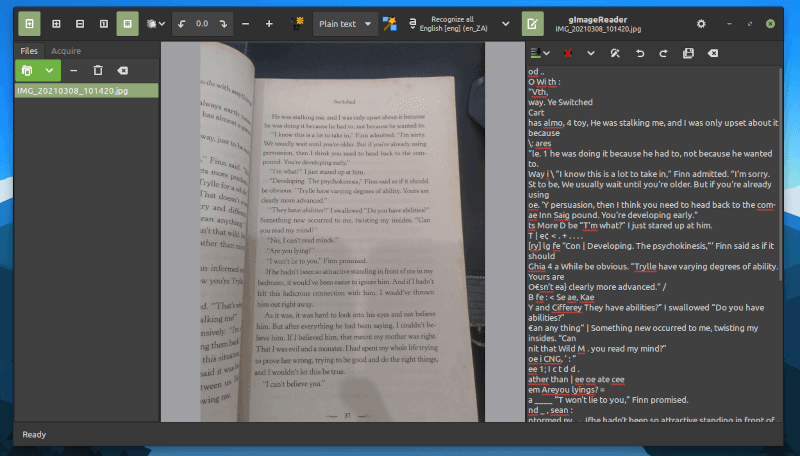
为了简化事情,gImageReader 可以方便地从 PDF 文件或包含任何类型文本的图像中提取文本。
无论您需要它进行拼写检查还是翻译,它都应该对特定用户组有用。
总结一下列表中的功能,您可以使用它执行以下操作:
从磁盘、扫描设备、剪贴板和屏幕截图添加 PDF 文档和图像
旋转图像的能力
用于调整亮度、对比度和分辨率的常用图像控件
直接通过应用程序扫描图像
能够一次性处理多个图像或文件
手动或自动识别区域定义
识别纯文本或 hOCR 文档
编辑器显示识别的文本
可以对提取的文本进行拼写检查
从 hOCR 文档转换/导出为 PDF 文档
将提取的文本导出为 .txt 文件
跨平台(Windows)
在 Linux 上安装 gImageReader
注意:您需要显式安装 Tesseract 语言包才能从软件管理器的图像/文件中进行检测。
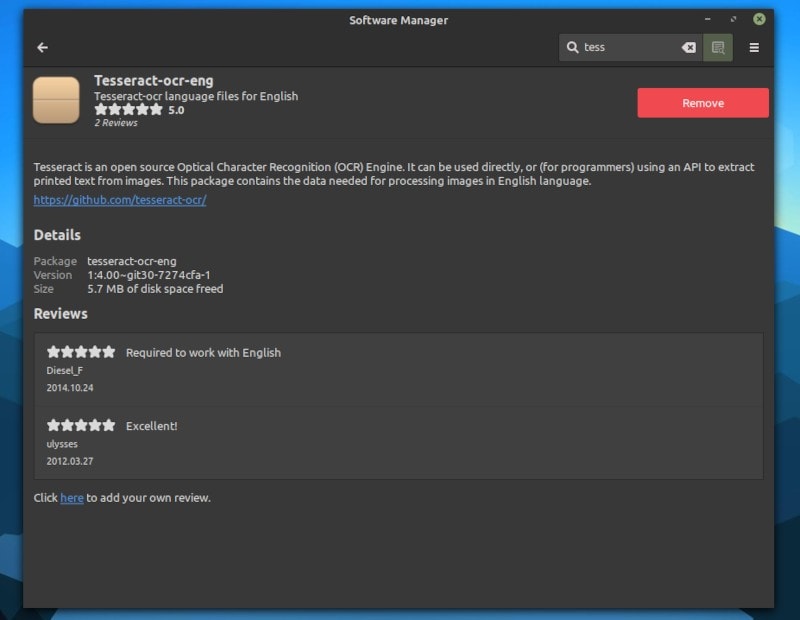
您可以在某些 Linux 发行版(例如 Fedora 和 Debian)的默认存储库中找到 gImageReader。
对于 Ubuntu,您需要添加 PPA,然后安装。为此,您需要在终端中输入以下内容:
sudo add-apt-repository ppa:sandromani/gimagereader
sudo apt update
sudo apt install gimagereader您还可以从 openSUSE 的构建服务中找到它,AUR 将成为 Arch Linux 用户的地方。
存储库和包的所有链接都可以在其 GitHub 页面中找到。
gImageReader 体验
gImageReader 是一个非常有用的工具,可以在需要时从图像中提取文本。当您尝试使用 PDF 文件时,效果非常好。
对于从智能手机拍摄的照片中提取图像,检测结果很接近,但有点不准确。也许当您扫描某些内容时,可以更好地识别文件中的字符。
因此,您必须亲自尝试一下,看看它对您的用例有多有效。我在Linux Mint 20.1(基于Ubuntu 20.04)上尝试过。
我只是在设置中管理语言时遇到问题,但没有找到快速解决方案。如果您遇到该问题,您可能需要对其进行故障排除并详细了解如何修复它。
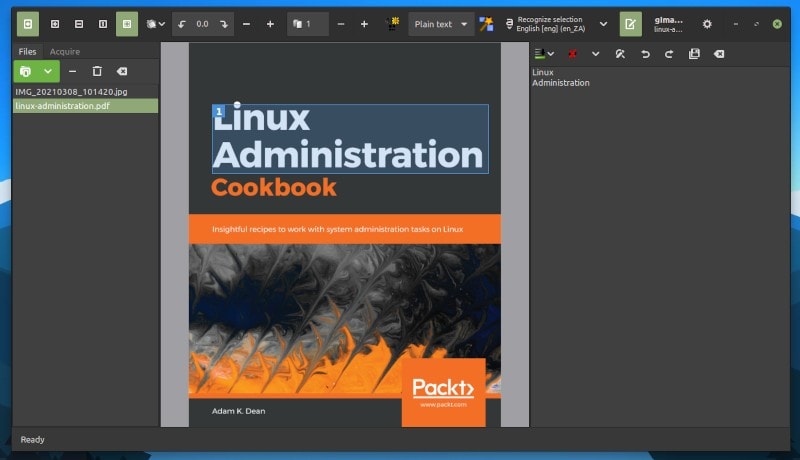
除此之外,它工作得很好。
请尝试一下,让我知道它对你有什么作用!如果您知道类似(甚至更好)的东西,请在下面的评论中告诉我。