如何在 Linux 上获取 CUDA 核心数
在本文中,您将了解如何在 Linux 上获取 CUDA 核心数。作为文本主题,我们将获得 NVIDIA GeForce RTX 3080 上的 CUDA 核心数量。
在本教程中您将学习:
如何使用 NVIDIA 驱动程序获取 CUDA 核心数
如何使用 NVIDIA CUDA 工具包获取 CUDA 核心数
NVIDIA RTX 3080 CUDA 核心数
如何使用 NVIDIA 驱动程序在 Linux 上获取 CUDA 核心数
第一步是为您的 NVIDIA 显卡安装合适的驱动程序。为此,请遵循我们的 NVIDIA 驱动程序安装指南之一。
准备好后,只需使用以下命令选项执行
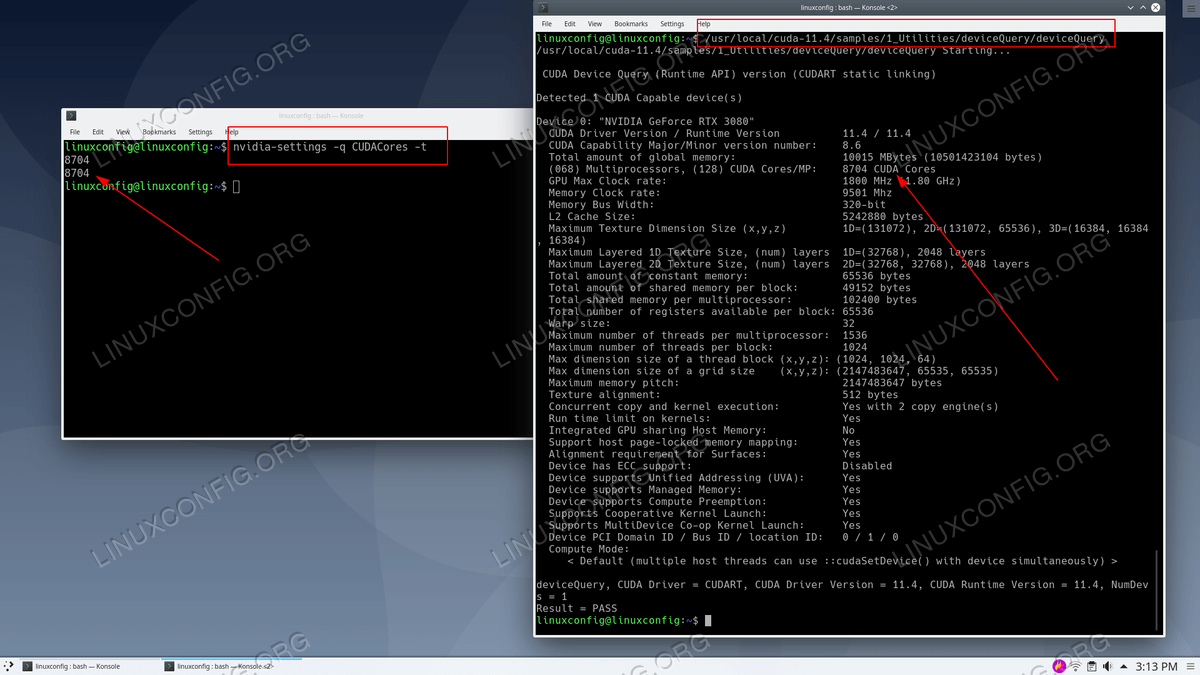
nvidia-settings命令即可。例如,这里是我们的 NVIDIA RTX 3080 GPU 的 CUDA 核心数:$ nvidia-settings -q CUDACores -t 8704 8704
如何使用 NVIDIA 驱动程序在 Linux 上获取 CUDA 核心数
乌班图 20.04:
$ wget https://developer.download.nvidia.com/compute/cuda/repos/ubunt4/x86_64/cuda-ubunt4.pin$ sudo mv cuda-ubunt4.pin /etc/apt/preferences.d/cuda-repository-pin-600$ sudo apt-key adv --fetch-keys https://developer.download.nvidia.com/compute/cuda/repos/ubunt4/x86_64/7fa2af80.pub$ sudo add-apt-repository "deb https://developer.download.nvidia.com/compute/cuda/repos/ubunt4/x86_64/ /"$ sudo apt-get update$ sudo apt-get -y install cudaDebian 10:
# apt-key adv --fetch-keys https://developer.download.nvidia.com/compute/cuda/repos/debian10/x86_64/7fa2af80.pub# add-apt-repository "deb https://developer.download.nvidia.com/compute/cuda/repos/debian10/x86_64/ /"# add-apt-repository contrib# apt-get update# apt-get -y install cudaRHEL 8/CentOS 8:
$ sudo dnf config-manager --add-repo https://developer.download.nvidia.com/compute/cuda/repos/rhel8/x86_64/cuda-rhel8.repo$ sudo dnf clean all$ sudo dnf -y module install nvidia-driver:latest-dkms$ sudo dnf -y install cuda作为 CUDA 工具包安装的一部分,找到其
deviceQuery目录。$ locate deviceQuery上述命令应返回类似于以下内容的输出:
$ locate deviceQuery /usr/local/cuda-11.4/extras/demo_suite/deviceQuery /usr/local/cuda-11.4/samples/1_Utilities/deviceQuery /usr/local/cuda-11.4/samples/1_Utilities/deviceQuery/Makefile /usr/local/cuda-11.4/samples/1_Utilities/deviceQuery/NsightEclipse.xml /usr/local/cuda-11.4/samples/1_Utilities/deviceQuery/deviceQuery.cpp ...
编译
deviceQuery源代码:$ cd /usr/local/cuda-11.4/samples/1_Utilities/deviceQuery # make执行新编译的二进制文件以获取 NVIDIA GPU 的 CUDA 核心数量。 :
$ ./deviceQuery ./deviceQuery Starting... CUDA Device Query (Runtime API) version (CUDART static linking) Detected 1 CUDA Capable device(s) Device 0: "NVIDIA GeForce RTX 3080" CUDA Driver Version / Runtime Version 11.4 / 11.4 CUDA Capability Major/Minor version number: 8.6 Total amount of global memory: 10015 MBytes (10501423104 bytes) (068) Multiprocessors, (128) CUDA Cores/MP: 8704 CUDA Cores GPU Max Clock rate: 1800 MHz (1.80 GHz) Memory Clock rate: 9501 Mhz Memory Bus Width: 320-bit L2 Cache Size: 5242880 bytes Maximum Texture Dimension Size (x,y,z) 1D=(131072), 2D=(131072, 65536), 3D=(16384, 16384, 16384) Maximum Layered 1D Texture Size, (num) layers 1D=(32768), 2048 layers Maximum Layered 2D Texture Size, (num) layers 2D=(32768, 32768), 2048 layers Total amount of constant memory: 65536 bytes Total amount of shared memory per block: 49152 bytes Total shared memory per multiprocessor: 102400 bytes Total number of registers available per block: 65536 Warp size: 32 Maximum number of threads per multiprocessor: 1536 Maximum number of threads per block: 1024 Max dimension size of a thread block (x,y,z): (1024, 1024, 64) Max dimension size of a grid size (x,y,z): (2147483647, 65535, 65535) Maximum memory pitch: 2147483647 bytes Texture alignment: 512 bytes Concurrent copy and kernel execution: Yes with 2 copy engine(s) Run time limit on kernels: Yes Integrated GPU sharing Host Memory: No Support host page-locked memory mapping: Yes Alignment requirement for Surfaces: Yes Device has ECC support: Disabled Device supports Unified Addressing (UVA): Yes Device supports Managed Memory: Yes Device supports Compute Preemption: Yes Supports Cooperative Kernel Launch: Yes Supports MultiDevice Co-op Kernel Launch: Yes Device PCI Domain ID / Bus ID / location ID: 0 / 1 / 0 Compute Mode: < Default (multiple host threads can use ::cudaSetDevice() with device simultaneously) > deviceQuery, CUDA Driver = CUDART, CUDA Driver Version = 11.4, CUDA Runtime Version = 11.4, NumDevs = 1 Result = PASS