如何在 Debian 11 上安装 Apache Spark
本教程适用于这些操作系统版本
- Debian 11(Bullseye)
- Debian 10(Buster)
在此页
- 先决条件
- 安装Java
- 安装 Apache Spark
- 启动 Apache Spark
- 访问 Apache Spark 网络用户界面
- 通过命令行连接 Apache Spark
- 停止主从
- 结论
Apache Spark 是一个免费的开源通用分布式计算框架,旨在提供更快的计算结果。它支持多种用于流式处理、图形处理的 API,包括 Java、Python、Scala 和 R。通常,Apache Spark 可以在 Hadoop 集群中使用,但您也可以将其安装在独立模式下。
在本教程中,我们将向您展示如何在 Debian 11 上安装 Apache Spark 框架。
先决条件
- 运行 Debian 11 的服务器。
- 在服务器上配置了根密码。
安装Java
Apache Spark 是用 Java 编写的。因此,您的系统中必须安装 Java。如果没有安装,您可以使用以下命令安装它:
apt-get install default-jdk curl -y安装 Java 后,使用以下命令验证 Java 版本:
java --version您应该得到以下输出:
openjdk 11.0.12 2021-07-20
OpenJDK Runtime Environment (build 11.0.12+7-post-Debian-2)
OpenJDK 64-Bit Server VM (build 11.0.12+7-post-Debian-2, mixed mode, sharing)
安装 Apache Spark
在编写本教程时,Apache Spark 的最新版本是 3.1.2。您可以使用以下命令下载它:
wget https://dlcdn.apache.org/spark/spark-3.1.2/spark-3.1.2-bin-hadoop3.2.tgz下载完成后,使用以下命令解压缩下载的文件:
tar -xvzf spark-3.1.2-bin-hadoop3.2.tgz接下来,使用以下命令将提取的目录移动到 /opt:
mv spark-3.1.2-bin-hadoop3.2/ /opt/spark接下来,编辑 ~/.bashrc 文件并添加 Spark 路径变量:
nano ~/.bashrc添加以下行:
export SPARK_HOME=/opt/spark
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
保存并关闭文件,然后使用以下命令激活 Spark 环境变量:
source ~/.bashrc启动 Apache Spark
您现在可以运行以下命令来启动 Spark 主服务:
start-master.sh您应该得到以下输出:
starting org.apache.spark.deploy.master.Master, logging to /opt/spark/logs/spark-root-org.apache.spark.deploy.master.Master-1-debian11.out
默认情况下,Apache Spark 侦听端口 8080。您可以使用以下命令验证它:
ss -tunelp | grep 8080您将获得以下输出:
tcp LISTEN 0 1 *:8080 *:* users:(("java",pid=24356,fd=296)) ino:47523 sk:b cgroup:/user.slice/user-0.slice/session-1.scope v6only:0 <->
接下来,使用以下命令启动 Apache Spark 工作进程:
start-slave.sh spark://your-server-ip:7077访问 Apache Spark Web UI
您现在可以使用 URL http://your-server-ip:8080 访问 Apache Spark Web 界面。您应该在以下屏幕上看到 Apache Spark 主从服务:
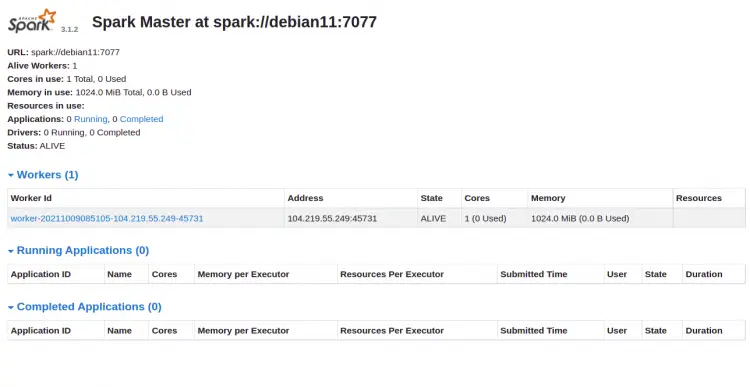
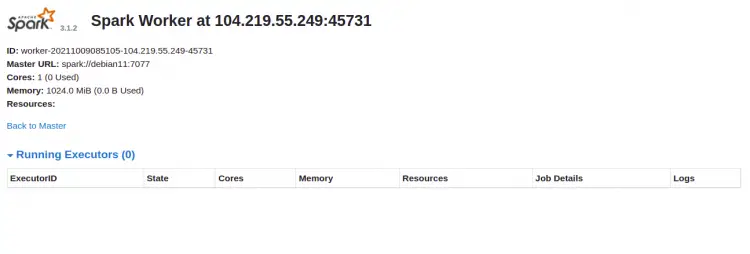
单击工人 ID。您应该在以下屏幕上看到您的工人的详细信息:
通过命令行连接 Apache Spark
如果你想通过它的命令 shell 连接到 Spark,运行下面的命令:
spark-shell连接后,您将获得以下界面:
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 3.1.2
/_/
Using Scala version 2.12.10 (OpenJDK 64-Bit Server VM, Java 11.0.12)
Type in expressions to have them evaluated.
Type :help for more information.
scala>
如果你想在 Spark 中使用 Python。您可以使用 pyspark 命令行实用程序。
首先,使用以下命令安装 Python 版本 2:
apt-get install python -y安装后,您可以使用以下命令连接 Spark:
pyspark连接后,您应该得到以下输出:
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/__ / .__/\_,_/_/ /_/\_\ version 3.1.2
/_/
Using Python version 3.9.2 (default, Feb 28 2021 17:03:44)
Spark context Web UI available at http://debian11:4040
Spark context available as 'sc' (master = local[*], app id = local-1633769632964).
SparkSession available as 'spark'.
>>>
停止主从
首先,使用以下命令停止从属进程:
stop-slave.sh您将获得以下输出:
stopping org.apache.spark.deploy.worker.Worker
接下来,使用以下命令停止主进程:
stop-master.sh您将获得以下输出:
stopping org.apache.spark.deploy.master.Master
结论
恭喜!您已在 Debian 11 上成功安装 Apache Spark。您现在可以在您的组织中使用 Apache Spark 来处理大型数据集