如何在 Ubuntu 22.04 上安装 Apache Spark
Apache Spark 是一个免费、开源、通用的数据处理引擎,数据科学家使用它对大量数据执行极快的数据查询。它使用内存数据存储将查询和数据直接存储在集群节点的主内存中。它提供 Java、Scala、Python 和 R 语言的高级 API。它还支持一组丰富的高级工具,例如 Spark SQL、MLlib、GraphX 和 Spark Streaming。
这篇文章将向您展示如何在 Ubuntu 22.04 上安装 Apache Spark 数据处理引擎。
先决条件
- 运行 Ubuntu 22.04 的服务器。
- 服务器上配置了 root 密码。
安装Java
Apache Spark 基于 Java。所以你的服务器上必须安装Java。如果没有安装,可以通过运行以下命令来安装:
apt-get install default-jdk curl -y安装 Java 后,使用以下命令验证 Java 安装:
java -version您将得到以下输出:
openjdk version "11.0.15" 2022-04-19
OpenJDK Runtime Environment (build 11.0.15+10-Ubuntu-0ubuntu0.22.04.1)
OpenJDK 64-Bit Server VM (build 11.0.15+10-Ubuntu-0ubuntu0.22.04.1, mixed mode, sharing)
安装 Apache Spark
在撰写本教程时,Apache Spark 的最新版本是 Spark 3.2.1。您可以使用 wget 命令下载它:
wget https://dlcdn.apache.org/spark/spark-3.2.1/spark-3.2.1-bin-hadoop3.2.tgz下载完成后,使用以下命令解压缩下载的文件:
tar xvf spark-3.2.1-bin-hadoop3.2.tgz接下来,将下载的文件解压到 /opt 目录:
mv spark-3.2.1-bin-hadoop3.2/ /opt/spark接下来,编辑 .bashrc 文件并定义 Apache Spark 的路径:
nano ~/.bashrc在文件末尾添加以下行:
export SPARK_HOME=/opt/spark
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
保存并关闭文件,然后使用以下命令激活 Spark 环境变量:
source ~/.bashrc接下来,创建一个专用用户来运行 Apache Spark:
useradd spark接下来,将 /opt/spark 的所有权更改为 Spark 用户和组:
chown -R spark:spark /opt/spark为 Apache Spark 创建 Systemd 服务文件
接下来,您需要创建一个服务文件来管理 Apache Spark 服务。
首先,使用以下命令为 Spark master 创建服务文件:
nano /etc/systemd/system/spark-master.service添加以下行:
[Unit]
Description=Apache Spark Master
After=network.target
[Service]
Type=forking
User=spark
Group=spark
ExecStart=/opt/spark/sbin/start-master.sh
ExecStop=/opt/spark/sbin/stop-master.sh
[Install]
WantedBy=multi-user.target
保存并关闭文件,然后为 Spark Slave 创建服务文件:
nano /etc/systemd/system/spark-slave.service添加以下行:
[Unit]
Description=Apache Spark Slave
After=network.target
[Service]
Type=forking
User=spark
Group=spark
ExecStart=/opt/spark/sbin/start-slave.sh spark://your-server-ip:7077
ExecStop=/opt/spark/sbin/stop-slave.sh
[Install]
WantedBy=multi-user.target
保存并关闭文件,然后重新加载 systemd 守护进程以应用更改:
systemctl daemon-reload接下来,使用以下命令启动并启用 Spark 主服务:
systemctl start spark-master
systemctl enable spark-master您可以使用以下命令检查 Spark master 的状态:
systemctl status spark-master您将得到以下输出:
? spark-master.service - Apache Spark Master
Loaded: loaded (/etc/systemd/system/spark-master.service; disabled; vendor preset: enabled)
Active: active (running) since Thu 2022-05-05 11:48:15 UTC; 2s ago
Process: 19924 ExecStart=/opt/spark/sbin/start-master.sh (code=exited, status=0/SUCCESS)
Main PID: 19934 (java)
Tasks: 32 (limit: 4630)
Memory: 162.8M
CPU: 6.264s
CGroup: /system.slice/spark-master.service
??19934 /usr/lib/jvm/java-11-openjdk-amd64/bin/java -cp "/opt/spark/conf/:/opt/spark/jars/*" -Xmx1g org.apache.spark.deploy.mast>
May 05 11:48:12 ubuntu2204 systemd[1]: Starting Apache Spark Master...
May 05 11:48:12 ubuntu2204 start-master.sh[19929]: starting org.apache.spark.deploy.master.Master, logging to /opt/spark/logs/spark-spark-org>
May 05 11:48:15 ubuntu2204 systemd[1]: Started Apache Spark Master.
完成后,您可以继续下一步。
访问 Apache Spark
此时,Apache Spark 已启动并监听 8080 端口。您可以使用以下命令查看:
ss -antpl | grep java您将得到以下输出:
LISTEN 0 4096 [::ffff:69.28.88.159]:7077 *:* users:(("java",pid=19934,fd=256))
LISTEN 0 1 *:8080 *:* users:(("java",pid=19934,fd=258))
现在,打开 Web 浏览器并使用 URL http://your-server-ip:8080 访问 Spark Web 界面。您应该在以下页面上看到 Apache Spark 仪表板:
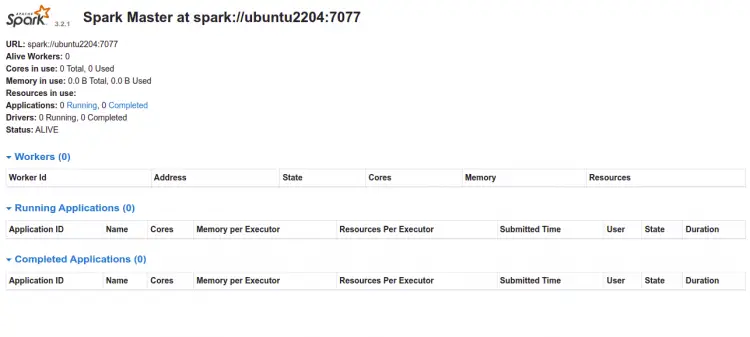
现在,启动 Spark Slave 服务并使其在系统重新启动时启动:
systemctl start spark-slave
systemctl enable spark-slave可以使用以下命令检查Spark从服务的状态:
systemctl status spark-slave您将得到以下输出:
? spark-slave.service - Apache Spark Slave
Loaded: loaded (/etc/systemd/system/spark-slave.service; disabled; vendor preset: enabled)
Active: active (running) since Thu 2022-05-05 11:49:32 UTC; 4s ago
Process: 20006 ExecStart=/opt/spark/sbin/start-slave.sh spark://69.28.88.159:7077 (code=exited, status=0/SUCCESS)
Main PID: 20017 (java)
Tasks: 35 (limit: 4630)
Memory: 185.9M
CPU: 7.513s
CGroup: /system.slice/spark-slave.service
??20017 /usr/lib/jvm/java-11-openjdk-amd64/bin/java -cp "/opt/spark/conf/:/opt/spark/jars/*" -Xmx1g org.apache.spark.deploy.work>
May 05 11:49:29 ubuntu2204 systemd[1]: Starting Apache Spark Slave...
May 05 11:49:29 ubuntu2204 start-slave.sh[20006]: This script is deprecated, use start-worker.sh
May 05 11:49:29 ubuntu2204 start-slave.sh[20012]: starting org.apache.spark.deploy.worker.Worker, logging to /opt/spark/logs/spark-spark-org.>
May 05 11:49:32 ubuntu2204 systemd[1]: Started Apache Spark Slave.
现在,返回 Spark Web 界面并刷新网页。您应该在以下页面上看到添加的 Worker:
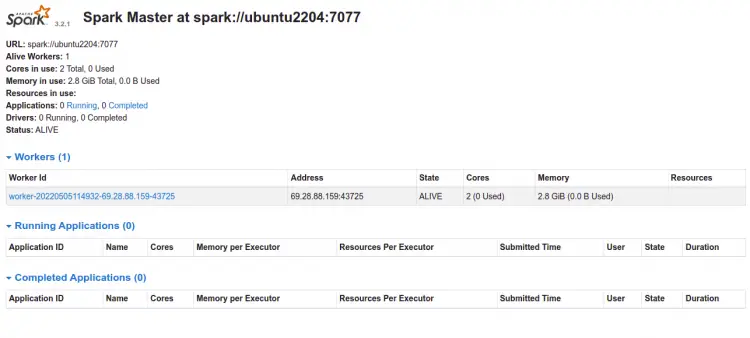
现在,单击工人。您应该在以下页面上看到工作人员信息:
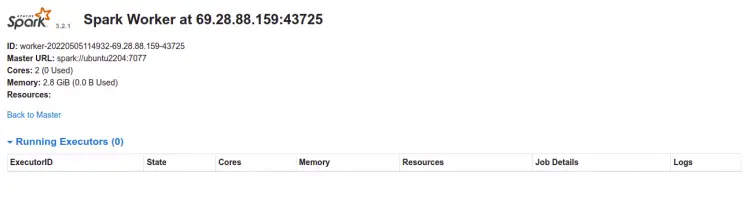
如何访问 Spark Shell
Apache Spark 还提供了一个 Spark-shell 实用程序来通过命令行访问 Spark。您可以使用以下命令访问它:
spark-shell您将得到以下输出:
WARNING: An illegal reflective access operation has occurred
WARNING: Illegal reflective access by org.apache.spark.unsafe.Platform (file:/opt/spark/jars/spark-unsafe_2.12-3.2.1.jar) to constructor java.nio.DirectByteBuffer(long,int)
WARNING: Please consider reporting this to the maintainers of org.apache.spark.unsafe.Platform
WARNING: Use --illegal-access=warn to enable warnings of further illegal reflective access operations
WARNING: All illegal access operations will be denied in a future release
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
22/05/05 11:50:46 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Spark context Web UI available at http://ubuntu2204:4040
Spark context available as 'sc' (master = local[*], app id = local-1651751448361).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 3.2.1
/_/
Using Scala version 2.12.15 (OpenJDK 64-Bit Server VM, Java 11.0.15)
Type in expressions to have them evaluated.
Type :help for more information.
scala>
要退出 Spark shell,请运行以下命令:
scala> :quit如果您是 Python 开发人员,则使用 pyspark 访问 Spark:
pyspark您将得到以下输出:
Python 3.10.4 (main, Apr 2 2022, 09:04:19) [GCC 11.2.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
WARNING: An illegal reflective access operation has occurred
WARNING: Illegal reflective access by org.apache.spark.unsafe.Platform (file:/opt/spark/jars/spark-unsafe_2.12-3.2.1.jar) to constructor java.nio.DirectByteBuffer(long,int)
WARNING: Please consider reporting this to the maintainers of org.apache.spark.unsafe.Platform
WARNING: Use --illegal-access=warn to enable warnings of further illegal reflective access operations
WARNING: All illegal access operations will be denied in a future release
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
22/05/05 11:53:17 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/__ / .__/\_,_/_/ /_/\_\ version 3.2.1
/_/
Using Python version 3.10.4 (main, Apr 2 2022 09:04:19)
Spark context Web UI available at http://ubuntu2204:4040
Spark context available as 'sc' (master = local[*], app id = local-1651751598729).
SparkSession available as 'spark'.
>>>
按 CTRL + D 键退出 Spark shell。
结论
恭喜!您已在 Ubuntu 22.04 上成功安装 Apache Spark。您现在可以开始在 Hadoop 环境中使用 Apache Spark。有关更多信息,请阅读 Apache Spark 文档页面。